
{kind=link}
{kind=link}
In the world of artificial intelligence, the ability to understand and generate language based on visual inputs is a game-changer. The Figure 02 Vision-Language API is one of the latest tools pushing the boundaries of what AI can do in this space. But the question remains: Is it truly ready for real-world integration? Let’s dive into this fascinating technology and examine its readiness, potential, challenges, and future applications.
The Rise of Vision-Language Models
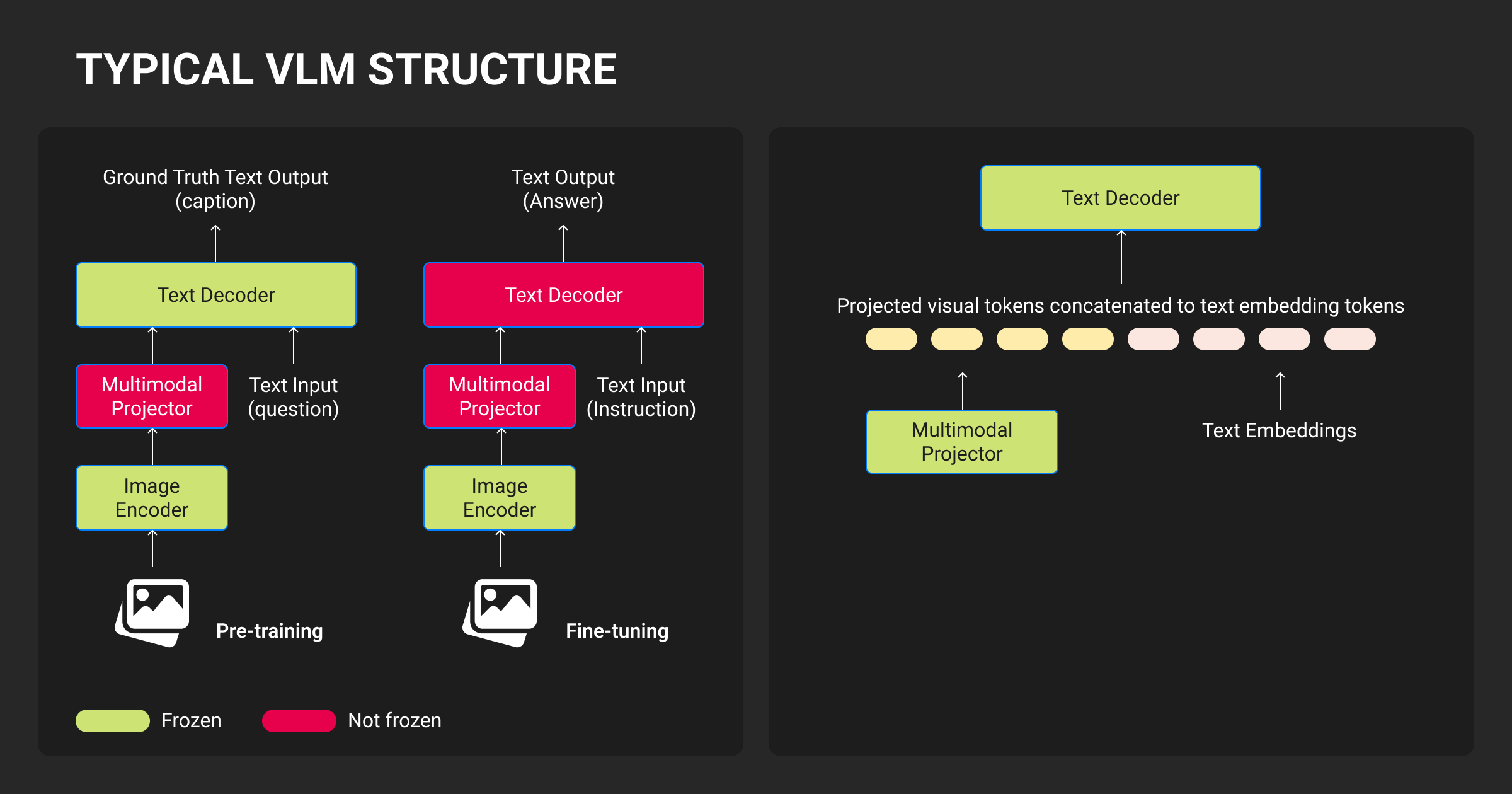
Before we explore the specifics of the Figure 02 API, it’s crucial to understand what vision-language models (VLMs) are and why they’ve gained so much attention. Essentially, VLMs are designed to bridge the gap between computer vision and natural language processing (NLP). These models enable machines to “see” the world and describe it with text, or conversely, understand text and generate related visual content.
The most famous example of such models are OpenAI’s CLIP (Contrastive Language-Image Pre-training) and DALL·E. These models can match images with corresponding descriptions, or even generate entirely new images based on textual descriptions. The field has grown exponentially in recent years, with applications ranging from autonomous vehicles to personalized shopping experiences.
However, the Figure 02 Vision-Language API enters the fray with the promise of not just matching images with descriptions but also offering an even deeper level of interaction—one that could be tailored to more specific industries and use cases.
What is the Figure 02 Vision-Language API?
The Figure 02 Vision-Language API is a cutting-edge tool designed to combine the capabilities of computer vision and natural language processing in a single platform. Through the use of deep learning models, it can interpret images and videos and return detailed, contextual language-based insights. This API allows developers to build applications that can understand and generate visual descriptions, captions, tags, and even generate new images from text-based prompts.
Unlike more generic models, the Figure 02 API has been fine-tuned for real-world applications. It promises faster processing, more accurate interpretation, and the ability to handle complex multi-modal queries (combining both vision and language inputs). Whether it’s for use in e-commerce, content creation, healthcare, or autonomous driving, the API promises a highly specialized toolkit for integrating vision-language capabilities.
The Promise of Real-World Integration
1. Accessibility Across Industries:
One of the most compelling aspects of the Figure 02 Vision-Language API is its broad applicability. Let’s explore a few industries where the technology could make a tangible impact.
- Healthcare: The API could help doctors by converting medical imaging into text-based reports, making it easier to review, search, and analyze patient data. In radiology, for instance, a system could analyze X-rays or MRI scans and generate detailed, accurate textual descriptions that assist healthcare professionals in diagnosing conditions more swiftly.
- E-commerce: For online retailers, the ability to automatically generate descriptive text for products, analyze customer images, and even provide personalized shopping experiences is groundbreaking. Imagine a shopping app that could look at a picture of an outfit you uploaded and suggest matching shoes or accessories in real time.
- Autonomous Vehicles: Vision-language models like Figure 02 could play a critical role in the development of self-driving cars. These cars need to understand not just the physical environment around them, but also context. For example, recognizing a stop sign and interpreting the word “STOP” together is essential for safe driving.
- Content Creation and Digital Media: The API can assist in generating descriptions for images, captions for social media, or even custom-designed visuals based on user prompts. This could significantly speed up the creative process in industries such as advertising, filmmaking, and digital marketing.
2. Flexibility for Developers:
The API is designed to be developer-friendly, offering a wide range of features for custom integrations. It supports various input formats, including images, videos, and even live feeds, and can return outputs in multiple languages. This flexibility allows businesses to integrate vision-language capabilities into their existing systems without overhauling their infrastructure.
3. Personalization and User-Centric Applications:
As with any AI-driven platform, personalization is a key selling point. The Figure 02 API has the potential to learn from user interactions and adapt its responses based on specific preferences. For instance, in a customer service scenario, the API could learn a user’s preferred communication style or tailor recommendations based on past behavior. This personalized approach could enhance user engagement and satisfaction.
Challenges to Overcome for Real Integration
Despite its incredible potential, the Figure 02 Vision-Language API is not without challenges that must be addressed before it can be seamlessly integrated into real-world applications.
1. Data Privacy Concerns:
Any AI system that processes visual and textual data runs the risk of exposing sensitive information. In industries like healthcare and finance, the privacy of patient or customer data is paramount. Developers using the API must ensure that data is anonymized and protected according to strict data privacy regulations like GDPR or HIPAA.
2. Accuracy and Reliability:
While the Figure 02 API is impressive in its capabilities, the accuracy of its outputs is critical for real-world integration. Misinterpretation of visual data, especially in high-stakes fields like healthcare or autonomous driving, can have severe consequences. Rigorous testing and fine-tuning are essential to ensure that the model’s predictions are trustworthy.
3. Ethical Considerations:
AI models have a history of reinforcing biases present in the data used to train them. The Figure 02 API is no exception, and developers need to be aware of potential ethical pitfalls, such as discrimination in automated decision-making or the generation of inappropriate content. Ensuring fairness and transparency in the API’s operations is crucial to maintaining trust with users.
4. Computational Resources:
Vision-language models are resource-intensive, requiring significant computational power to process and generate outputs. For businesses looking to integrate the Figure 02 API, this means higher operational costs, especially when dealing with large-scale applications. Optimizing the model for efficiency without sacrificing performance will be essential for widespread adoption.
5. Integration Complexity:
While the API is developer-friendly, integrating it into existing systems can be complex. The systems and processes already in place may need to be restructured to accommodate the API, which could be time-consuming and costly. Moreover, ongoing maintenance and updates will be necessary to ensure the API continues to meet evolving business needs.
The Future of Vision-Language APIs
The integration of vision-language models into various industries is still in its early stages. However, the potential is enormous, and as AI technology continues to evolve, we can expect to see more sophisticated, context-aware systems that seamlessly combine visual understanding with language generation.
As for the Figure 02 Vision-Language API, its future is bright, but its true potential will depend on how effectively it can overcome the challenges discussed above. If the developers continue to refine the API’s accuracy, reduce computational costs, and address ethical concerns, it could revolutionize industries as diverse as healthcare, automotive, e-commerce, and media.
In Conclusion:
The Figure 02 Vision-Language API holds great promise for revolutionizing how we interact with AI systems across various sectors. While it is already a powerful tool, the real test will be how effectively it can be integrated into real-world applications, balancing performance with privacy, ethics, and cost. The road to full integration may be challenging, but the potential rewards are immense, making it an exciting technology to watch in the years to come.