
{kind=link}
{kind=link}
Introduction
The race for artificial intelligence supremacy spreads far beyond social chatbots and recommendation engines — it has charged straight into the physical world: autonomous cars and humanoid robots. At this frontier, Figure AI and Tesla’s Full Self‑Driving (FSD) represent two distinctly ambitious yet radically different visions of what intelligent machines can be. One aims to build general‑purpose humanoid robots capable of reasoning and manipulating objects in the world using vision‑language‑action (VLA) models. The other strives to deliver fully autonomous vehicles via a full‑stack neural network approach trained on massive real‑world driving data.
This article digs deep into the technical philosophies, strengths, limitations, and future prospects of both approaches — and explores a key question: Can Figure’s AI be smarter than Tesla’s full‑stack AI? What “smarter” means here will depend on the domain — whether physical dexterity, real‑world adaptability, general intelligence, or narrowly‑optimized task performance.
Tesla’s Full‑Stack AI — A Vertical Integration Powerhouse
A Vision‑Centric Autonomy Stack
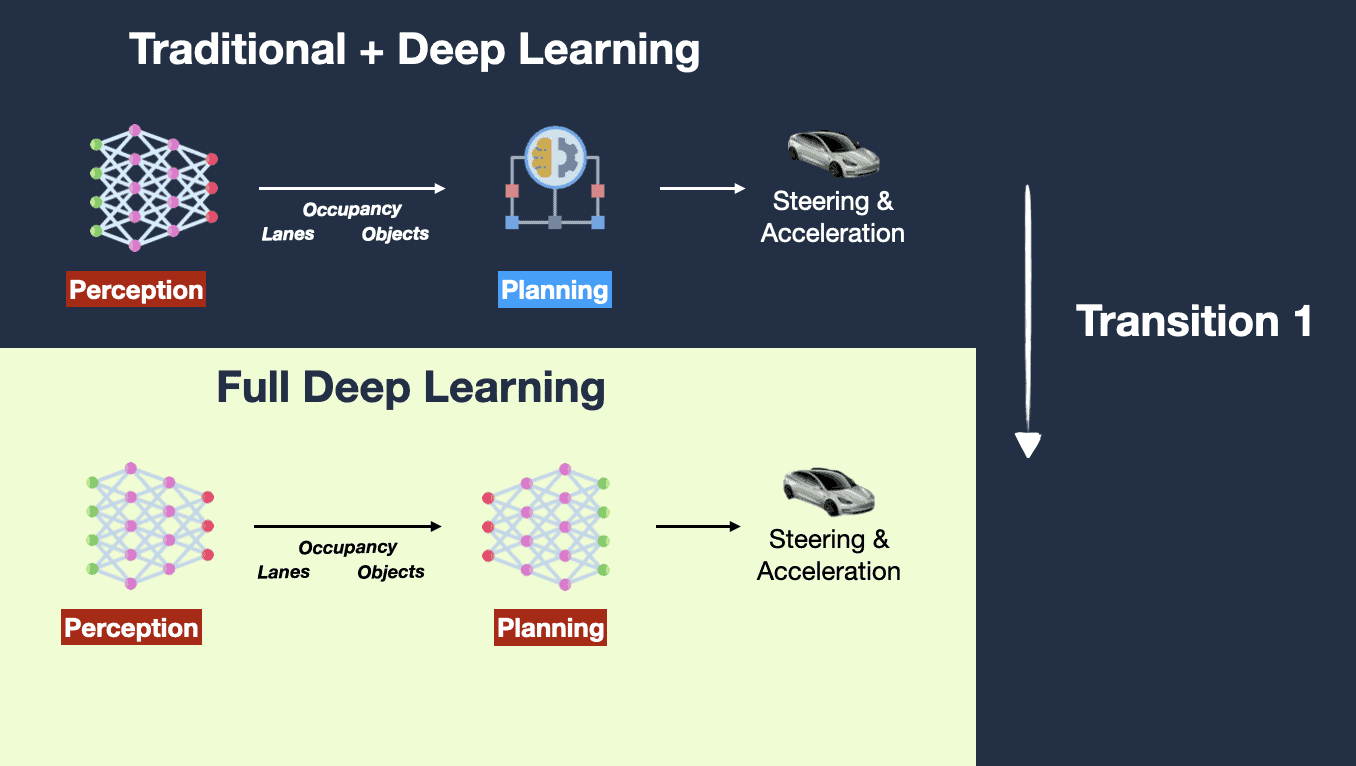
Tesla’s autonomous AI stack is fundamentally vision‑based. The company deliberately eschews traditional sensor modalities like lidar and radar, choosing instead to rely primarily on arrays of cameras and deep neural networks to perceive the world around the car. This philosophy — sometimes called vision‑only autonomy — is entrenched in Tesla’s design for both cars and robots like Optimus, its humanoid.
At its core:
- Tesla’s Full Self‑Driving (FSD) uses a set of deep neural networks trained end‑to‑end on millions of real driving hours collected from its vast fleet, a dataset no competitor can yet match.
- FSD v12 represented a seismic shift from traditional programming logic to neural networks that replace tens of thousands of handcrafted rules with learned behaviors — some would call it “ChatGPT for cars.”
- Custom silicon and tight hardware‑software integration reduce latency and enable complex models to run efficiently in real time inside the car.
Tesla’s end‑to‑end vision‑centric approach aims for general driving intelligence — to continuously learn and adapt from real world data.
Bragging Rights — But Still Supervised
Tesla’s FSD is powerful, but it is not truly autonomous according to mainstream classification standards. Its current Full Self‑Driving (Supervised) mode still requires active human supervision. Despite its name, the system does not achieve full autonomy (SAE Level 5) yet.
That said, Tesla’s approach offers several notable strengths:
- Scale of learning: Millions of vehicles continuously contribute data, giving Tesla unrivaled real‑world edge‑case training.
- Vertical integration: Tesla controls the entire stack — hardware, software, data capture, and cumulative model training — potentially enabling faster iteration.
- Runtime pipeline: Neural networks process raw camera frames into robust predictions and planning signals, allowing the vehicle to react in complex environments.
This end‑to‑end coupling of vision, learning, and control is where the term full‑stack approach truly shines for Tesla — not only in autonomy but in positioning the company as an AI‑centric mobility provider.
Limitations and Real‑World Challenges
However, Tesla’s full‑stack approach isn’t without its critics:
- Lack of sensor redundancy (no lidar) means it must infer depth and spatial detail purely from vision — a data‑efficient but technically challenging goal.
- Continuous reliance on supervised features implies that fully driverless deployment at a massive scale isn’t here yet.
- Edge cases and rare scenarios remain a struggle for vision‑only systems.
Even Elon Musk has publicly acknowledged that FSD progress takes more time than expected — a hint that even Tesla’s vertical, full‑stack strategy must run through decades of iterative improvements.
Figure AI — A Vision‑Language‑Action Revolution
From Humanoid Robots to Generalized Intelligence
While Tesla’s AI is geared toward autonomous driving and logistics, Figure AI has carved its identity in humanoid robotics — an entirely different domain where physical interaction, multi‑sensory coordination, and reasoning from language are paramount.
Figure’s flagship technology is Helix, a Vision‑Language‑Action (VLA) model — a neural architecture that unifies perception, language understanding, and physical control in a single compact learning system.
What makes Helix special?
- Vision + Language + Control combined: Helix embeds not only perceptual understanding from visual inputs but also natural language processing to interpret human instructions. This makes physical task execution contextual — not just a sequence of preprogrammed actions.
- Task generalization: Unlike narrow, task‑specific robot control systems, Helix directly outputs robot motions from combined sensory and linguistic inputs, meaning it can pick up objects it has never seen before and adapt to new environments based on instructions.
- Embedded autonomy: Figure’s robots (like Figure 03) run Helix onboard low‑power GPUs, not reliant on remote servers, allowing real‑time interaction.
In many ways, Helix resembles a broader model of intelligence — akin to Large Language Models (LLMs) that interpret instructions and act upon them by reasoning through both visual and linguistic contexts.
Physical Dexterity and Adaptive Behaviors
Figure’s humanoid robots go beyond perception. They physically interact with the world — grasping objects, navigating cluttered spaces, and performing household or industrial tasks. This kind of embodied intelligence is historically one of the hardest frontiers in artificial intelligence.
Helix splits cognitive duties into two complementary systems:
- System 2: Understands scenes and language at lower frequency (~7–9 Hz), akin to high‑level reasoning.
- System 1: Executes low‑level motor actions at high frequency (~200 Hz), providing responsive control.
This dual model allows Figure robots to learn from instructions — and reason across vision, language, and action simultaneously.
Comparing the Philosophies
| Dimension | Tesla Full‑Stack FSD | Figure AI Helix |
|---|---|---|
| Core Domain | Autonomous driving (vehicles) | Humanoid robotics |
| AI Architecture | Vision‑based neural networks trained on real‑world driving data | Vision‑Language‑Action model combining perception, NLP, and control |
| Primary Learning Source | Fleet‑collected driving data | Multimodal training with language, vision, and manipulation datasets |
| Task Generalization | High for driving tasks; limited beyond that | High across various physical manipulation and reasoning roles |
| Hardware Dependency | Custom silicon + camera suite | Onboard GPUs + advanced sensors |
| Sensor Approach | Vision only | Vision + tactile + audio (multimodal) |
| Current Autonomy Level | Advanced assisted (not fully autonomous) | Emerging real‑world autonomous robot interactions |
| Scale Potential | Gigantic fleet + over‑the‑air updates | Depend on robotics manufacturing scale |
Can One Be Smarter Than the Other?
The phrase smarter than hides a critical ambiguity — smarter in what domain?
Driving Intelligence vs. Embodied Intelligence
Tesla’s full‑stack AI is specifically optimized for driving tasks — situational awareness under dynamic road conditions, multi‑agent interactions, high‑speed decision making, safety constraints, and continuous improvement from fleet data. In this domain, Tesla’s AI shines due to:
- Depth of real world data
- Decades‑worth of incremental autonomy system development
- Tight integration between software and hardware stacks
However, that doesn’t translate to generalizable physical intelligence outside its automotive realm.
Conversely, Figure’s AI is designed to solve embodied general tasks — interpreting language, perceiving 3D environments, and executing dexterity‑intensive physical actions. Even though humanoid robots are nascent and nowhere near perfect, their AI is structurally closer to open‑ended intelligence — capable of generalizing across tasks. This makes them “smarter” when performing diverse, interactive tasks beyond the narrow scope of driving.
Raw AI Capabilities and Learning
Tesla’s FSD is an extraordinary engineering feat, but its intelligence is narrow by design. Its neural networks are focused on vehicle control decisions, not open‑ended reasoning. By contrast, Helix’s VLA model integrates language reasoning and action, capturing a broader spectrum of intelligence akin to a generalist AI (even if not yet at human general intelligence).
Unlike Tesla’s model, which learns primarily from driving data, Helix learns from a rich tapestry of linguistic, visual, and manipulation experiences, enabling it to:
- Understand commands in natural language
- Deduce task goals from context
- Coordinate complex motor behaviors
This renders Helix more versatile, even if it’s still early in its development lifecycle.
Engineering vs. Scientific Innovation
Tesla’s strength lies in vertical integration and engineering scale — a massive, self‑reinforcing data ecosystem that accelerates optimized task performance. This is perhaps the best way to solve driving autonomy at an industrial scale. In contrast, Figure’s approach pushes the boundaries of scientific AI innovation in general intelligence for embodied robotics. It’s not as mature in deployment scale, but the breadth of capability potentially exceeds that of a specialized autonomous system.
The Future Trajectory — Who Has the Edge?
Near‑Term (1–3 Years)
- Tesla will likely continue incremental improvements in FSD and begin scaling Optimus deployment for factory and logistics roles.
- Figure will refine Helix and expand real‑world humanoid applications in homes, warehouses, and light industrial settings.
Mid‑Term (3–7 Years)
- Tesla’s data‑driven learning could push it closer to genuinely unsupervised autonomy for cars (Level 4/5) — though this remains unproven.
- Figure’s VLA systems could achieve generalized task intelligence, enabling robots to adapt to new instructions and unfamiliar environments.
Long‑Term (Beyond 7 Years)
- Tesla’s AI may dominate transportation autonomy if it solves edge cases and regulatory hurdles.
- Figure’s AI might transcend narrow domains, leading towards a platform capable of a wide range of intelligent tasks.
In essence, Tesla will likely build better autonomous drivers. Figure might build smarter generalists.