
{kind=link}
{kind=link}
Robot manipulation — the ability for a robot to grasp, move, adjust, assemble, or otherwise interact physically with the world — has always represented one of the most formidable frontiers in robotics. Human hands effortlessly perform manipulation tasks ranging from picking up a cup to performing delicate surgical operations. For robots, these same tasks remain astonishingly complex because of the intricate coordination of perception, planning, control, and environment variability. Traditional control systems and scripted automation were once the norm, but they rely on rigid programming and fail in unstructured environments. This is where deep imitation learning steps in — an approach inspired by how humans learn through observation, demonstration, and example.
Deep imitation learning blends the power of deep neural networks with the intuition of learning from expert demonstrations. Rather than relying on manual coding or trial‑and‑error exploration alone, robots trained with deep imitation learning watch expert demonstrations — often of humans performing tasks — and map these into control policies that can be deployed in real robots. This paradigm has rapidly accelerated capabilities in robotic manipulation, especially in scenarios where handcrafted rules or pure reinforcement learning fall short.
What Is Deep Imitation Learning?
At its core, imitation learning (IL) enables an agent to learn behavior by observing demonstrations from an expert — typically human operators or pre‑recorded demonstrations — rather than acquiring skills solely through reinforcement signals or reward functions. In robotics, this means a robot can watch examples of successful manipulation and learn to generalize those actions to new situations.
When deep learning models are used to approximate policies from high‑dimensional input like vision, proprioception, or force feedback, we get deep imitation learning: the combination of neural networks with imitation learning techniques. This powerful mix enables a robot to jump from raw sensory inputs — such as camera images — directly to motion commands or control strategies, learning complex mappings end‑to‑end.
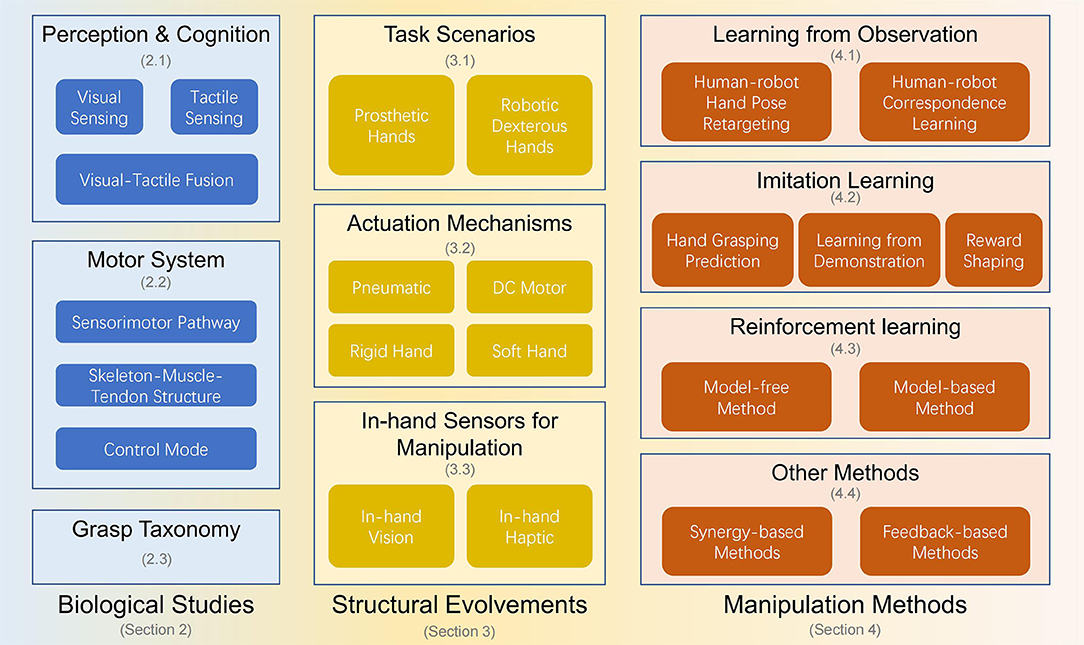
There are several key approaches within imitation learning:
- Behavior cloning (BC): Directly mimics expert behavior by learning a mapping from states to actions as a supervised learning problem.
- Inverse reinforcement learning (IRL): Infers the underlying reward function that the expert is optimizing and uses that to learn a policy.
- Generative adversarial imitation learning (GAIL): Uses generative models to match the distributions of expert and agent behaviors.
Each has strengths and weaknesses, but all contribute to improved robot learning efficiency compared to traditional methods.
Why It Matters for Robotic Manipulation
Robot manipulation typically involves high‑dimensional state and action spaces, combined with complex environmental dynamics like friction, occlusions, or unpredictable interactions. Hard‑coding solutions to cover all possible variations is infeasible. Even reinforcement learning (RL) — while powerful — is often data‑inefficient and slow when trained from scratch in complex physical environments.
Deep imitation learning addresses these challenges by providing:
1. Faster Skill Acquisition
Because imitation learning trains policies using data from expert demonstrations, it avoids the lengthy trial‑and‑error exploration process that standard RL requires. Instead of discovering behaviors from scratch, the robot inherits a strong prior from expert examples and can fine‑tune strategies based on those priors. This dramatically speeds up learning, especially in environments where real‑world interactions are expensive or risky (e.g., surgical manipulation or industrial assembly).
2. Handling High‑Dimensional Sensory Inputs
Deep networks excel at processing high‑dimensional sensory data such as images, depth maps, and tactile feedback. By combining them with imitation learning, robots can learn to directly translate visual and sensory observations into action commands without handcrafted feature engineering. This ability is crucial when performing tasks like precision grasping or object reorientation in cluttered environments.
3. Generalization Across Tasks
While one obvious challenge in robotics is learning one task well, an even greater challenge is generalizing that skill to novel tasks or contexts. Deep imitation learning — especially when trained on diverse demonstration datasets — enables robots to generalize beyond the exact demonstrations they saw. Some research even achieves zero‑shot generalization to new tasks the robot has never encountered before, highlighting the power of large demonstration sets combined with expressive deep models.
4. Bridging Simulation and Reality
Robotics researchers often train models in simulation before deploying them in the physical world. Deep imitation learning facilitates this by allowing robots to learn robust policies from simulated demonstrations and then refine them using real‑world examples. By carefully designing demonstrations and domain adaptation techniques, the gap between simulated performance and real deployment can be minimized.
Real‑World Examples of Deep Imitation Learning in Action
Vision‑Guided Grasping
A robot learns to pick up various objects simply by observing human demonstrations of successful grasps. Vision systems feed raw images into neural networks trained via imitation learning, producing control commands that replicate those grasp behaviors. The results: robots can handle previously unseen objects with high success rates — a significant leap over rigid, programmed grasping.

Complex Dexterous Manipulation
Using techniques inspired by human teleoperation or virtual reality demonstrations, robots learn to perform complex two‑handed tasks like tool use, assembly, or precision placement — tasks once considered beyond the reach of autonomous systems. Deep imitation learning enables mapping from sensory perception to control trajectories in a single end‑to‑end framework.
Interactive Human‑Robot Teaching
In interactive imitation learning variants, a human can provide continual feedback while the robot executes tasks, enabling iterative refinement of behaviors in real time. This supports tasks where static demonstrations are not enough and iterative guidance improves performance. Such interactive frameworks result in more robust manipulation even in dynamic environments.
Core Advantages Over Traditional Approaches
Higher Sample Efficiency
Standard reinforcement learning can require thousands or millions of interactions with the environment to learn effective policies. Deep imitation learning dramatically reduces these requirements via expert demonstration data, accelerating real‑world learning.
Robustness to Variation
Because policies are trained on varied demonstrations and deep networks can capture subtle sensory cues, deep imitation learning policies tend to be more robust to environmental uncertainties — like lighting changes or object shifts — than rule‑based systems.
Lower Entry Barrier for Complex Tasks
Traditional robot programming requires deep expertise in control theory and kinematics. Deep imitation learning allows even non‑experts to provide demonstrations — perhaps via teleoperation or video — bypassing the need for specialist coders.
Challenges and Limitations
Despite its remarkable promise, deep imitation learning is not without challenges. These include:
- Data Quality Dependence: The effectiveness of learned policies depends heavily on the quality and diversity of demonstration data. Poor or inconsistent demonstrations can lead to poor performance or overfitting.
- Covariate Shift: Policies trained using behavior cloning may drift when encountering states not seen in training demonstrations, leading to errors compounding over time. Techniques like dataset aggregation (DAgger) help mitigate this.
- Generalization Complexity: While impressive, generalizing to vastly different tasks remains challenging. Current research is focused on leveraging language, video, or multimodal embeddings to encode task descriptions for better generalization.
- Real‑World Transfer: Bridging simulation to reality still poses difficulties, requiring careful domain adaptation techniques and safety mechanisms.
The Future of Deep Imitation Learning in Robot Manipulation
Looking forward, deep imitation learning is poised to become a cornerstone of robot intelligence. Research directions include:
- Multi‑task and lifelong learning where robots continually learn new manipulation skills over time.
- Language‑guided policies where instruction in natural language augments demonstration data.
- Self‑supervised auxiliary learning to improve robustness and adaptability with minimal human effort.
As datasets grow, and as deep models become more expressive and efficient, the barriers between human and robot capability in physical tasks will continue to shrink — bringing us closer to robots that not only mimic but also innovate upon human behaviors.